Big Ball of Mud,中文名称“一坨翔”。本文的上篇:”噢,你的代码像一坨翔。然后呢?“,我们从解决方案出发,妄图通过不断尝试不同的药来解决问题。这种从解决方案出发的态度随处可见,比如问啥叫微服务,服务多微才叫微服务。JSON+HTTP好,还是 Protobuf 好。RPC好还是走消息队列好。不要问什么是微服务,要问微服务能够给你带来什么。如果不知道什么叫”好“,你怎么知道哪个好呢?从老板的角度来说,他们真正只在乎两件事情:
- 系统要稳定,别挂
- 出活要快,我让你们加什么功能,赶紧就给加上
然后他们假装会在乎
- 少用一点机器和带宽给公司省点钱
- 别出错,让用户的体验好一点
实际上打心底里,最重要的还就是前两点。少用一点机器根本不用你上 Protobuf 来省出来,消息队列再怎么高效,都没有本质的提升。什么叫质的提升?某厂一个小姑娘带着老板的尚方宝剑去各个业务组敲打一圈,一下子收归几千台空闲机。这就叫质的提升。当我们得知真相之后,正在做各种性能优化的码农的心是崩溃的。和稳定性与交付速度相比,性能和成本绝对不是什么值得在台面上讨论的问题。即便要解决这个问题,也轮不到用技术手段来解决。就像中国的银行有所谓的“窗口指导”一样,领机器的时候卡严一点,比什么都管用。
用户体验也是一样的。互联网企业最常做的事情是灰度,拿一部份用户做小白鼠。另外一个常见的做法是最终一致性,碰上点故障那就是最终也一致不了。个别用户碰到一点奇葩的现象实在是太平常了。老板们关心是大部分用户的体验是不是好,至于长尾的体验,实在是顾不过来的。业务逻辑是不是写得非常完善,事务处理是不是天衣无缝。这个都不是最重要的事情。让系统来解决99.9%的事情,剩下的0.1%,交给RD和客服去处理就好了。这对有手写raft协议的追求的人来说是一件很崩溃的事情,但是这个是对大部分业务来说最经济的选择。不需要你搞一个多完备的东西出来,偶尔出错就出错呗。
那么稳定性和交付速度就是最重要的两个指标了。
其实咋切都行
把一个单体应用切分为多个进程,独立部署是必然的。
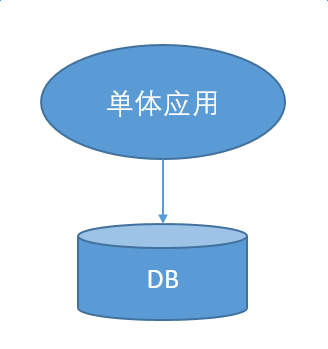
我们应该拆分成,咳咳,独立的微服务。这不是废话么。问题是怎么拆?我现在觉得,其实怎么拆都行,因为都比合在一起要强。

单体应用的最大问题是它一个部署就阻塞了所有其他人的上线。而众所周知,我们谁都没有测试,至少是没有可以保证业务不挂掉的测试。真正的冒烟测试,都是用上线灰度的方式来做的。剩下的功能测试,是接下来数天里用线上开关的方式逐步地放量来做的。线下的测试么,我就呵呵了,你懂的。单体应用的存在,使得每个功能可以被分配到灰度时间变少了。这么多公司都在拆微服务,最重要的收益是让每个模块能够独享自己的灰度时间,从而大幅减少因为上线破坏旧的功能引起的故障。
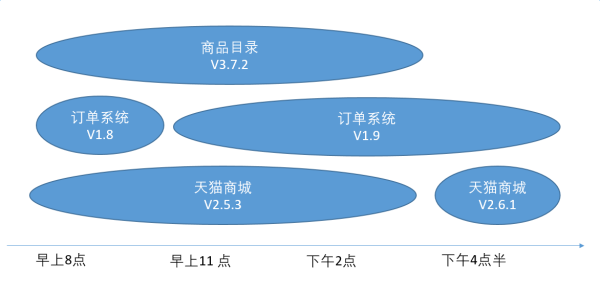
无论怎么拆分,都会比合在一起要好。这里”好”,指的是少出故障。实际上是怎么切的,反而不是那么重要的事情,只要能切得开,哪怕你是复制一份代码呢?
甩锅宝典
我的判断是,90%的一坨翔不是因为业务自身有多么多么复杂。而是因为不懂得拒绝,总是做老好人,什么事情都干。就是因为你总是做劳模,替所有人干所有的事,屎盆子才会扣在你的头上。要想避免一坨翔,要从学会甩锅开始做起。传你五条甩锅心法,保平安
- 立字据
- 透传
- 让他们来取
- 如果还是要我推,我就和你们同归于尽
- 相信队友
所有这些招数,和上篇里列举的那些架构模式没有本质区别,不过是换了一个说法。但是我们这次很明白自己的需求是什么。提高团队的自主性,不要被周边系统连累。一个需求,尽量一个团队搞定。减少跨团队沟通的需要,提高所有人的效率。如果开的药方可以做到这一点,就是一个好药方。
你给我立字据
甩锅心法第一则,立字据
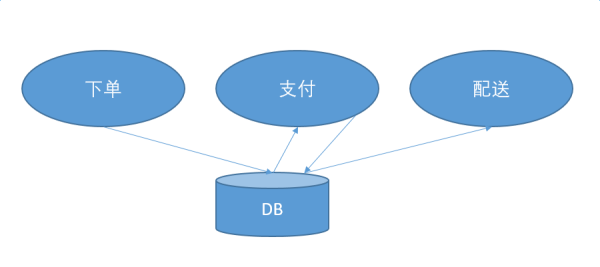
哪怕是亲兄弟,也要明算账。坚决不要和其他的服务共用db。我的是我的,你的是你的。
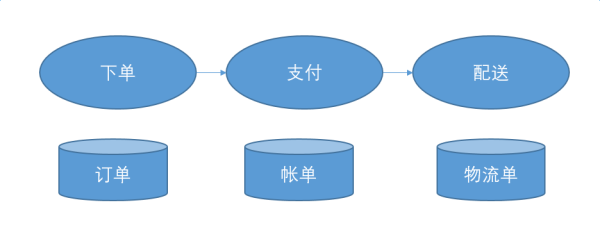
各做各的业务,你要存什么,你自己存去。别挤到一个庞大的Order表里。让你和其他的服务之间,有明确的起止边界,是甩锅最重要的事情。当出了问题的时候,你的责任非常清楚,看看输入,看看输出,一目了然。要不然某个Order上的字段错了,到底是谁写错了都搞不清楚,大家都有读写权限。最极端的情况,流程的每一个步骤都可以切出一个独立的服务出来。
让每个服务有自己的存储,自己独立去面对最终客户,目的是为了让有需求来的时候,每个服务的团队可以更快响应。他们上可接客户,下可接存储,拥有了最大的自主性。而与其他的团队之间也有很清晰的接口(连产品经理都可以说得出来的),从而最小化了沟通成本。
其实所有在数据库里有 1:1 关系的表都有类似的问题。我们可以选择一个表n个字段。也可以选择把表分为两个,然后1:1对应。从快速试错,满足业务需求的角度,拆分出独立的表是更优的做法。也就可以表达为,如果要加一个功能,优先选择建一个新的模块,把这个特例的需求搞定。而不是去修改现有的表,把功能写到现有代码里。
代码重用,从来就不是老板们关心的事情。快速实现需求才是。从90年代的OO理论,到现代的微服务。我觉得最大的进步就是大家觉醒了,快速实现 != 代码重用。与其给场景A加两个字段,给场景B加三个字段。不如连同代码和数据,一切都切分出去好了。
透传
甩锅心法第二招,透传

在查询接口上最恶心的事情是要把一堆杂七杂八的东西都放在一起返回。甚至很多数据都不属于你,是别的团队提供的。要想减少你替别人做嫁衣(想一想,对方年终奖会分给你多少?),最佳的办法是甩锅。与其让别人返回一个enum给你,然后你吭哧吭哧地翻译成中文,拼装出其他需要的数据。直接开一个map透传的接口,你要给用户什么数据,你自己搞,爷不伺候了。因为你提供的是透传的接口,后端的系统有什么字段要加,也不会再来找你了。
无论前台是一种什么形式
- 富客户端,JSON API
- HTML页面
- IFRAME拼装的页面
都有办法从前到后透传,技术上都不是问题。如果可能,尽量让客户端取多次,在前台界面拼装。如果可能的话,让一个团队为最终结果负责,而不是做成两个团队来接力的模式。接力掉棒了,就会有扯皮的事情。
学会拒绝,让他们来取
做业务流程的同学,总是会被其他的兄弟部门找过来。你能不能在用户下单的时候,调我一下接口,做个xyz啊?你能不能在送达了之后,把配送时间写到某个redis里,我们数据分析要用哇?
别做老好人,学会拒绝。凡是和我的本质工作不相关的,请不要让我来实现。我把事件放到kafka里,你们自己来拿。RPC 和消息队列最本质的区别,不是网络开销,不是提高并发,而是职责的反转。
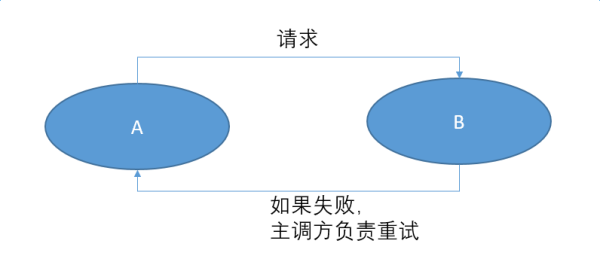
在 RPC 模式下,责任是在 A 团队的。如果 B 挂了,A 要负责重试。如果 B 一直挂,A 团队的负责人要接告警,然后打电话给B团队的人。
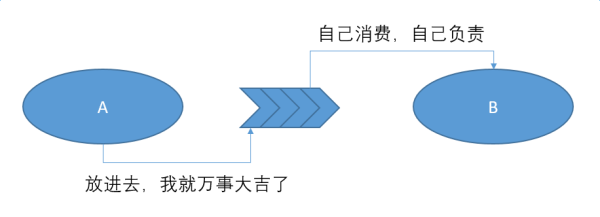
在消息队列的模式下,A是甩锅甩得很彻底的。没有人会闲的没事,帮 B 去监控一下他消费的offset。那不是我的责任,是你的责任。
B有两个常见的借口:
- 我不知道怎么消费队列,我给你个http接口,你来call一下,能有多难
- 队列里的数据不全啊,我还需要xyz
别慌,该甩的锅,坚决要甩。不能有妇人之仁。
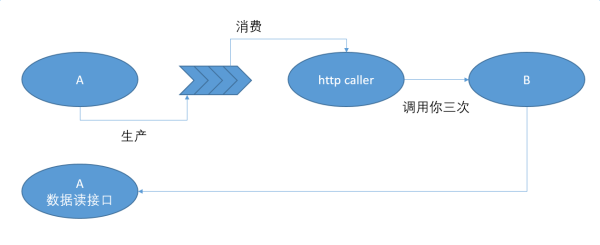
让消息队列的团队,额外提供一个 http caller 帮助残废的B去消费数据。怎么消费好搞,让 B 自己和基础架构的人去谈。A,概不负责。
如果消费的时候需要一些关联的数据,A提供读的接口,B自己来取。如果单条读太慢,可以提供批量读的接口。用户调用你的RPC的接口也不会把所有的数据都给你啊,还不是要读数据库么。为什么消费队列的时候就指望队列里有你处理逻辑的所有需要的数据呢?
在某个时间点上要发生的事情,不一定要一个地方都写完了。把事件放入队列,让相关方自己来取。他们自己去负责自己的事情,去取自己需要的数据。
与之同归于尽
好说话的合作伙伴,通过透传和写队列,都可以搞定。但是世界并不是这么简单的
- 我的强依赖他们的数据啊,他们的返回值我需要用
- 我给用户的返回值上的数据是他们提供的,走消息队列搞不定啊
- 这个事情现在不发生,晚一点就没意义了。走队列没收益嘛
确实是我自己的业务逻辑需要,比如我需要读订单,需要读用户信息。你能够让db的读接口也走队列么?肯定不行嘛。总是会有一些服务和别的服务不一样,你是甩不掉的。你们必须紧密协作,完成共同的kpi。
问题是如何判断,你依赖的服务是真的必要的强依赖,还是强赖着不走?我现在觉得最有效的手段是,问他愿不愿意跟你同归于尽。
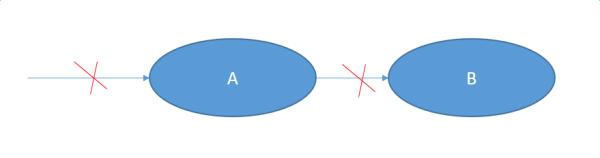
做为A,你去问B这个问题:如果你挂了,我也连累地挂了。然后每分钟几百万的损失你来承担,ok不ok?
如果B的答案是ok,我们共同来担这个责任。这就是真爱哇。如果B犹豫了,你就知道这是个假的伙伴。因为稳定性是老板最关注的事情,只有拿这个去切,才能真正切开。如果你问B,你愿不愿意走Kafka?B肯定会说,RPC不是走得好好的么。
哪怕在你的返回值上,有B提供的数据,也是同样的问题。还是问你自己这个问题。当B挂的时候,你是宁愿这个字段是空呢,还是让整个接口都挂掉?部分字段为空,大不了体验受损,也肯定是好过整体故障的。
这个“you jump, I jump”的问题,不仅仅对接口这个级别有效。更可以深入到字段的级别。也许A必须及时调用B,哪怕B挂了,A确实要负责B的重试。因为A和B共同推动了业务流程的前进,不把棒可靠地交到了B手里,A和B都没有好果子吃。但是并不代表,B提的一切要求就是合理的了。也许B给你提了一个20多个字段的接口,未必每个字段都是必须的。还是同样的做法,问问你自己,是希望某个字段为空,还是要死保稳定性。
在稳定性的高压下,一切同步接口都有变成异步的可能。哪怕99%正常的时候是同步调用,在那1%的故障场景下,所有人都可以接受一个异步的体验的,总好过挂掉的体验。而现在的中间件技术,提供的是要么全RPC,要么全异步的非黑即白的解决方案。并没有特别好的现成的方案来支持“平时是同步的,故障时改成异步的”这样的用法。
相信队友
和外部的系统打交道,我们一般有这么两招
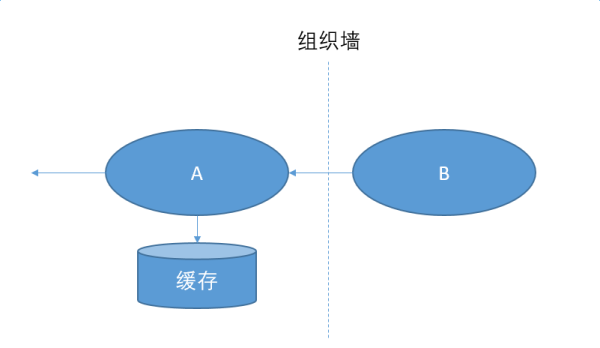
缓存一份对方提供的数据。提高访问速度,在B挂掉的时候,提供兜底方案。
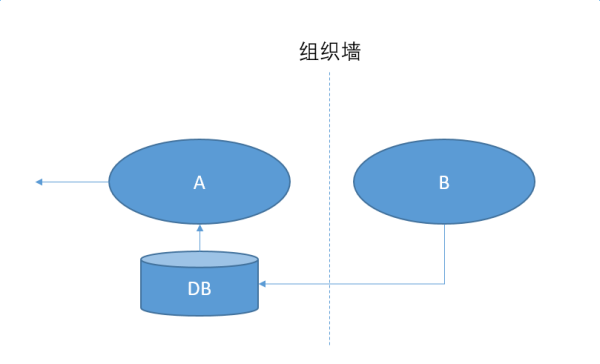
第二种做法是不直接依赖B,只订阅 B 的变化,写入自己的数据库。
这两种模式在你挂了,没法让B来背锅的场合是可以的。比如B是一个外部的国企。你就把B的可用性的责任,背到了自己的身上。如果B是你的队友,你要相信他们。你依赖的缓存是同机房的某台机器,B也可以把他的服务部署到你的机房啊。依赖自己的缓存,和依赖B没有本质区别。从全公司的角度来说,大家都做一份缓存,只是多复制了一份数据而已。和B签订好SLA,如果B挂了,慢了,让他们来背锅。
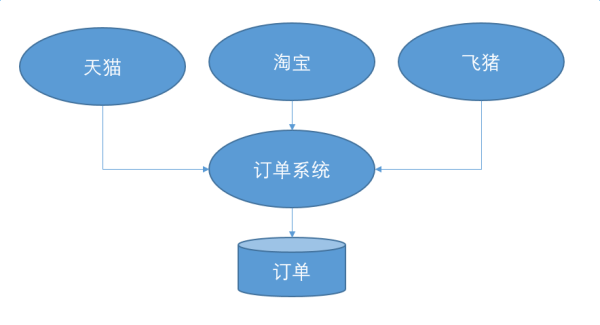
这种把一个存储前档一个数据服务的做法,有什么作用?如果只是增删改查的话确实没有啥用。如果只是解决分库分表,那确实不如改名叫dbproxy得了。为啥要搞出这样的队友来?我自己依赖数据库不行么?在前台应用比较丰富的情况,一些公共的业务上的规则要得到保证(比如全平台封禁)只能在中台来做。
甩锅第五招,相信你的队友,让他们提供SLA,有些底,你是不用兜的。
总结
因为稳定性的需求,切分是绝对必须的。做好灰度发布是最最重要的事情。
切分就是一个学会拒绝做老好人,不断甩锅的过程。按照我给的几条心法,没有什么锅是不能往外甩的了。
最后解放思想,不要固守什么模式什么原则。评价好坏只有两条硬性指标:系统是不是稳定,是不是能快速响应需求变化。
愿各位少谈一点主义,多解决一点问题。各司其职,多写点代码,少开些会,早点下班。
作者:陶文
链接:https://zhuanlan.zhihu.com/p/25192112
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
转载请注明:飞飞的个人网站 » 噢,你的代码像一坨翔。甩锅呗!